
La optimización de motores de búsqueda, en su sentido más básico, se basa en una cosa por encima de todas las demás: las arañas de los motores de búsqueda rastrean e indexan su sitio.
Pero casi todos los sitios web tendrán páginas que no querrá incluir en esta exploración.
Por ejemplo, ¿realmente desea que su política de privacidad o las páginas de búsqueda internas aparezcan en los resultados de Google?
En el mejor de los casos, estos no hacen nada para atraer tráfico a su sitio de forma activa y, en el peor de los casos, podrían desviar el tráfico de páginas más importantes.
Afortunadamente, Google permite a los webmasters decirles a los robots de los motores de búsqueda qué páginas y contenido rastrear y qué ignorar. Hay varias formas de hacer esto, la más común es usar un archivo robots.txt o la etiqueta meta robots.
Tenemos una excelente y detallada explicación de los entresijos de robots.txt, que definitivamente deberías leer.
Pero en términos de alto nivel, es un archivo de texto sin formato que vive en la raíz de su sitio web y sigue el Protocolo de exclusión de robots (REP).
Robots.txt proporciona a los rastreadores instrucciones sobre el sitio en su conjunto, mientras que las etiquetas de meta robots incluyen instrucciones para páginas específicas.
Algunas etiquetas de meta robots que puede emplear incluyen índiceque le dice a los motores de búsqueda que agreguen la página a su índice; sin índiceque le dice que no agregue una página al índice ni la incluya en los resultados de búsqueda; seguirque indica a un motor de búsqueda que siga los enlaces de una página; no seguirque le dice que no siga los enlaces, y una gran cantidad de otros.
Tanto las etiquetas robots.txt como las etiquetas meta robots son herramientas útiles para mantener en su caja de herramientas, pero también hay otra forma de instruir a los robots de los motores de búsqueda para que no indexen o no sigan: el X-Robots-Etiqueta.
¿Qué es la etiqueta X-Robots?
La etiqueta X-Robots es otra forma de controlar cómo las arañas rastrean e indexan sus páginas web. Como parte de la respuesta del encabezado HTTP a una URL, controla la indexación de una página completa, así como los elementos específicos de esa página.
Y mientras que usar etiquetas de meta robots es bastante sencillo, X-Robots-Tag es un poco más complicado.
Pero esto, por supuesto, plantea la pregunta:
¿Cuándo debería usar la etiqueta X-Robots?
De acuerdo a Google«Cualquier directiva que se pueda usar en una metaetiqueta de robots también se puede especificar como una etiqueta X-Robots».
Si bien puede configurar directivas relacionadas con robots.txt en los encabezados de una respuesta HTTP con la etiqueta meta robots y la etiqueta X-Robots, hay ciertas situaciones en las que desearía usar la etiqueta X-Robots, las dos más comunes. siendo cuando:
- Desea controlar cómo se rastrean e indexan sus archivos que no son HTML.
- Desea servir directivas en todo el sitio en lugar de en el nivel de una página.
Por ejemplo, si desea bloquear el rastreo de una imagen o video específico, el método de respuesta HTTP lo hace fácil.
El encabezado X-Robots-Tag también es útil porque le permite combinar múltiples etiquetas dentro de una respuesta HTTP o usar una lista de directivas separadas por comas para especificar directivas.
Tal vez no desee que una determinada página se almacene en caché y desee que no esté disponible después de una determinada fecha. Puede usar una combinación de etiquetas «noarchive» y «unavailable_after» para indicar a los robots de los motores de búsqueda que sigan estas instrucciones.
Esencialmente, el poder de la etiqueta X-Robots es que es mucho más flexible que la etiqueta meta robots.
La ventaja de usar un X-Robots-Tag con las respuestas HTTP es que le permite usar expresiones regulares para ejecutar directivas de rastreo en no HTML, así como aplicar parámetros en un nivel global más grande.
Para ayudarlo a comprender la diferencia entre estas directivas, es útil clasificarlas por tipo. Es decir, ¿son directivas de rastreador o directivas de indexador?
Aquí hay una práctica hoja de trucos para explicar:
| Directivas de rastreadores | Directivas del indexador |
| Robots.txt – utiliza las directivas de agente de usuario, permiso, rechazo y mapa del sitio para especificar dónde se permite rastrear y dónde no se permite rastrear a los bots de los motores de búsqueda en el sitio. | Etiqueta Meta Robots – le permite especificar y evitar que los motores de búsqueda muestren páginas particulares en un sitio en los resultados de búsqueda.
No seguir – le permite especificar enlaces que no deben transmitir autoridad o PageRank. X-Robots-etiqueta – le permite controlar cómo se indexan los tipos de archivos especificados. |
¿Dónde pones la etiqueta X-Robots?
Supongamos que desea bloquear tipos de archivos específicos. Un enfoque ideal sería agregar la etiqueta X-Robots a una configuración de Apache o un archivo .htaccess.
La etiqueta X-Robots se puede agregar a las respuestas HTTP de un sitio en una configuración de servidor Apache a través del archivo .htaccess.
Ejemplos del mundo real y usos de la etiqueta X-Robots
Eso suena genial en teoría, pero ¿cómo se ve en el mundo real? Vamos a ver.
Digamos que queremos que los motores de búsqueda no indexen los tipos de archivos .pdf. Esta configuración en los servidores Apache sería similar a la siguiente:
Header set X-Robots-Tag "noindex, nofollow"
En Nginx, se vería así:
location ~* .pdf$ {
add_header X-Robots-Tag "noindex, nofollow";
}
Ahora, veamos un escenario diferente. Digamos que queremos usar X-Robots-Tag para bloquear archivos de imagen, como .jpg, .gif, .png, etc., para que no sean indexados. Podría hacer esto con una etiqueta X-Robots que se vería como la siguiente:
Header set X-Robots-Tag "noindex"
Tenga en cuenta que comprender cómo funcionan estas directivas y el impacto que tienen entre sí es crucial.
Por ejemplo, ¿qué sucede si se localizan tanto la etiqueta X-Robots-Tag como la etiqueta metarobots cuando los bots rastreadores descubren una URL?
Si esa URL está bloqueada de robots.txt, entonces ciertas directivas de indexación y publicación no se pueden descubrir y no se seguirán.
Si se deben seguir las directivas, no se puede prohibir el rastreo de las URL que las contienen.
Buscar una etiqueta X-Robots
Hay algunos métodos diferentes que se pueden usar para verificar si hay una etiqueta X-Robots en el sitio.
La forma más sencilla de comprobarlo es instalar un extensión del navegador eso le dará información de X-Robots-Tag sobre la URL.
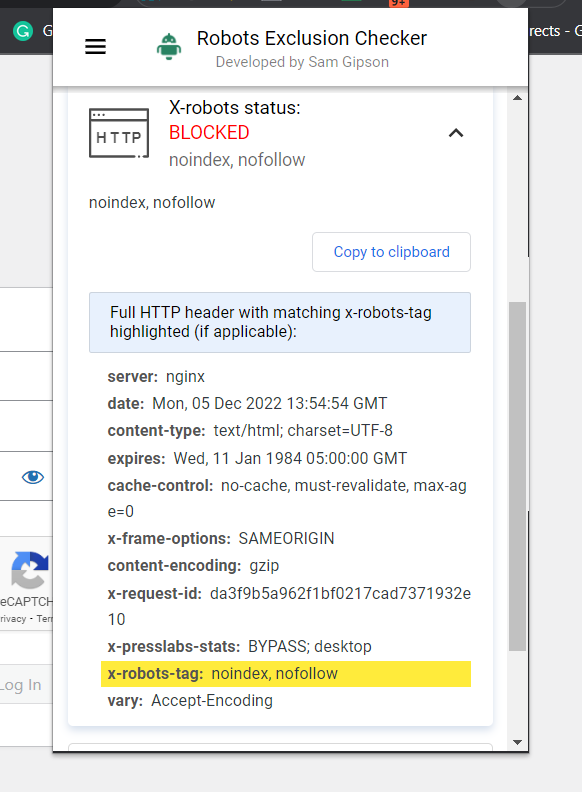 Captura de pantalla de Robots Exclusion Checker, diciembre de 2022
Captura de pantalla de Robots Exclusion Checker, diciembre de 2022Otro complemento que puede usar para determinar si se está usando una etiqueta X-Robots, por ejemplo, es el Complemento de desarrollador web.
Al hacer clic en el complemento en su navegador y navegar a «Ver encabezados de respuesta», puede ver los diversos encabezados HTTP que se utilizan.

Otro método que se puede usar para escalar con el fin de identificar problemas en sitios web con un millón de páginas es Screaming Frog.
Después de ejecutar un sitio a través de Screaming Frog, puede navegar a la columna «X-Robots-Tag».
Esto le mostrará qué secciones del sitio están usando la etiqueta, junto con qué directivas específicas.
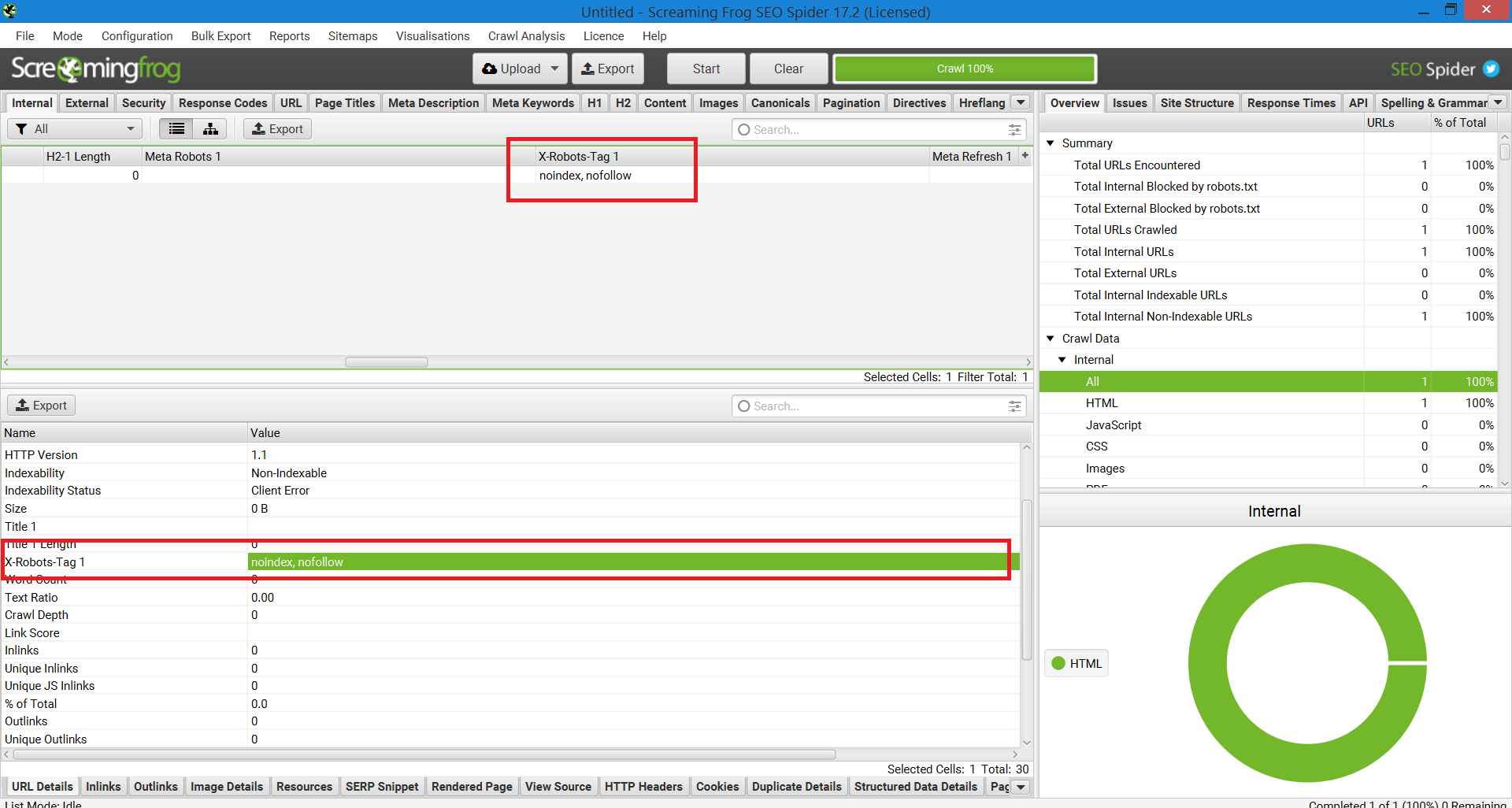 Captura de pantalla del informe Screaming Frog. X-Robot-Tag, diciembre de 2022
Captura de pantalla del informe Screaming Frog. X-Robot-Tag, diciembre de 2022Uso de X-Robots-Tags en su sitio
Comprender y controlar cómo los motores de búsqueda interactúan con su sitio web es la piedra angular de la optimización de motores de búsqueda. Y X-Robots-Tag es una poderosa herramienta que puede usar para hacer precisamente eso.
Solo tenga en cuenta: no está exento de peligros. Es muy fácil cometer un error y desindexar todo tu sitio.
Dicho esto, si estás leyendo este artículo, probablemente no seas un principiante en SEO. Siempre que lo use sabiamente, tómese su tiempo y verifique su trabajo, encontrará que la etiqueta X-Robots es una adición útil a su arsenal.
Más recursos:
- Google da a los sitios más control de indexación con la nueva etiqueta Robots
- 6 problemas comunes de Robots.txt y cómo solucionarlos
- SEO técnico avanzado: una guía completa
Imagen destacada: Song_about_summer/Shutterstock
#Todo #necesita #saber #sobre #encabezado #HTTP #XRobotsTag


