
Bard de Google se basa en el modelo de lenguaje LaMDA, entrenado en conjuntos de datos basados en contenido de Internet llamados Infiniset, de los cuales se sabe muy poco sobre el origen de los datos y cómo los obtuvieron.
El documento de investigación de LaMDA de 2022 enumera los porcentajes de diferentes tipos de datos utilizados para entrenar a LaMDA, pero solo el 12,5 % proviene de un conjunto de datos públicos de contenido rastreado de la web y otro 12,5 % proviene de Wikipedia.
Google es deliberadamente vago acerca de dónde proviene el resto de los datos extraídos, pero hay indicios de qué sitios se encuentran en esos conjuntos de datos.
Conjunto de datos Infiniset de Google
Google Bard se basa en un modelo de lenguaje llamado LaMDA, que es un acrónimo de Modelo de lenguaje para aplicaciones de diálogo.
LaMDA fue entrenado en un conjunto de datos llamado Infiniset.
Infiniset es una combinación de contenido de Internet que se eligió deliberadamente para mejorar la capacidad del modelo para participar en el diálogo.
El artículo de investigación de LaMDA (PDF) explica por qué eligieron esta composición de contenido:
“…esta composición fue elegida para lograr un rendimiento más sólido en las tareas de diálogo…manteniendo al mismo tiempo su capacidad para realizar otras tareas como la generación de código.
Como trabajo futuro, podemos estudiar cómo la elección de esta composición puede afectar la calidad de algunas de las otras tareas de PNL realizadas por el modelo”.
El trabajo de investigación hace referencia a diálogo y diálogosque es la ortografía de las palabras utilizadas en este contexto, dentro del ámbito de la informática.
En total, LaMDA se entrenó previamente en 1,56 billones de palabras de «datos de diálogo público y texto web.”
El conjunto de datos se compone de la siguiente combinación:
- 12,5 % de datos basados en C4
- 12,5% Wikipedia en inglés
- 12,5 % de documentos de código de programación de sitios web de preguntas y respuestas, tutoriales y otros
- 6,25% Documentos web en inglés
- 6,25 % de documentos web en idiomas distintos del inglés
- 50% datos de diálogos de foros públicos
Las dos primeras partes de Infiniset (C4 y Wikipedia) se componen de datos que se conocen.
El conjunto de datos C4, que se explorará en breve, es una versión especialmente filtrada del conjunto de datos Common Crawl.
Solo el 25% de los datos provienen de una fuente nombrada (el C4 conjunto de datos y Wikipedia).
El resto de los datos que componen la mayor parte del conjunto de datos de Infiniset, el 75 %, consiste en palabras extraídas de Internet.
El documento de investigación no dice cómo se obtuvieron los datos de los sitios web, de qué sitios web se obtuvieron ni ningún otro detalle sobre el contenido extraído.
Google solo usa descripciones generalizadas como «documentos web que no están en inglés».
La palabra «turbio» significa cuando algo no se explica y se oculta en su mayoría.
Murky es la mejor palabra para describir el 75% de los datos que Google usó para entrenar a LaMDA.
Hay algunas pistas que puede dar una idea general de qué sitios están incluidos en el 75% del contenido web, pero no podemos saberlo con certeza.
Conjunto de datos C4
C4 es un conjunto de datos desarrollado por Google en 2020. C4 significa «Cuerpo rastreado limpio colosal.”
Este conjunto de datos se basa en los datos de Common Crawl, que es un conjunto de datos de código abierto.
Acerca del rastreo común
Rastreo común es una organización sin fines de lucro registrada que rastrea Internet mensualmente para crear conjuntos de datos gratuitos que cualquiera puede usar.
La organización Common Crawl actualmente está dirigida por personas que han trabajado para la Fundación Wikimedia, ex Googlers, uno de los fundadores de Blekko, y cuenta como asesores con personas como Peter Norvig, Director de Investigación de Google y Danny Sullivan (también de Google).
Cómo se desarrolla C4 a partir del rastreo común
Los datos sin procesar de Common Crawl se limpian eliminando elementos como contenido reducido, palabras obscenas, lorem ipsum, menús de navegación, deduplicación, etc. para limitar el conjunto de datos al contenido principal.
El objetivo de filtrar datos innecesarios era eliminar galimatías y retener ejemplos de inglés natural.
Esto es lo que escribieron los investigadores que crearon C4:
“Para ensamblar nuestro conjunto de datos base, descargamos el texto extraído de la web de abril de 2019 y aplicamos el filtrado mencionado anteriormente.
Esto produce una colección de texto que no solo es mucho más grande que la mayoría de los conjuntos de datos utilizados para el entrenamiento previo (alrededor de 750 GB), sino que también comprende texto en inglés razonablemente limpio y natural.
Apodamos este conjunto de datos como «Colossal Clean Crawled Corpus» (o C4 para abreviar) y lo publicamos como parte de TensorFlow Datasets…»
También hay otras versiones sin filtrar de C4.
El artículo de investigación que describe el conjunto de datos C4 se titula, Explorando los límites del aprendizaje por transferencia con un transformador unificado de texto a texto (PDF).
Otro trabajo de investigación de 2021, (Documentación de grandes corpus de texto web: un estudio de caso sobre el colosal corpus limpio rastreado – PDF) examinó la composición de los sitios incluidos en el conjunto de datos C4.
Curiosamente, el segundo trabajo de investigación descubrió anomalías en el conjunto de datos C4 original que resultó en la eliminación de páginas web alineadas con hispanos y afroamericanos.
Las páginas web alineadas con hispanos fueron eliminadas por el filtro de la lista de bloqueo (groserías, etc.) a una tasa del 32 % de las páginas.
Las páginas web alineadas con afroamericanos se eliminaron a una tasa del 42%.
Presumiblemente, esas deficiencias se han solucionado…
Otro hallazgo fue que el 51,3% del conjunto de datos C4 consistía en páginas web alojadas en los Estados Unidos.
Por último, el análisis de 2021 del conjunto de datos C4 original reconoce que el conjunto de datos representa solo una fracción del total de Internet.
El análisis dice:
“Nuestro análisis muestra que, si bien este conjunto de datos representa una fracción significativa de un rasguño de Internet público, de ninguna manera es representativo del mundo de habla inglesa y abarca una amplia gama de años.
Al crear un conjunto de datos a partir de una copia de la web, informar los dominios de los que se extrae el texto es fundamental para comprender el conjunto de datos; el proceso de recopilación de datos puede conducir a una distribución de dominios de Internet significativamente diferente de lo que cabría esperar”.
Las siguientes estadísticas sobre el conjunto de datos C4 son del segundo trabajo de investigación que está vinculado anteriormente.
Los 25 principales sitios web (por número de tokens) en C4 son:
- patentes.google.com
- es.wikipedia.org
- es.m.wikipedia.org
- www.nytimes.com
- www.latimes.com
- www.theguardian.com
- revistas.plos.org
- www.forbes.com
- www.huffpost.es
- patentes.com
- www.scribd.com
- www.washingtonpost.com
- www.tonto.com
- ipfs.io
- www.frontiersin.org
- www.businessinsider.com
- www.chicagotribune.com
- www.booking.com
- www.theatlantic.com
- link.springer.com
- www.aljazeera.com
- www.kickstarter.com
- caselaw.findlaw.com
- www.ncbi.nlm.nih.gov
- www.npr.org
Estos son los 25 principales dominios de nivel superior representados en el conjunto de datos C4:
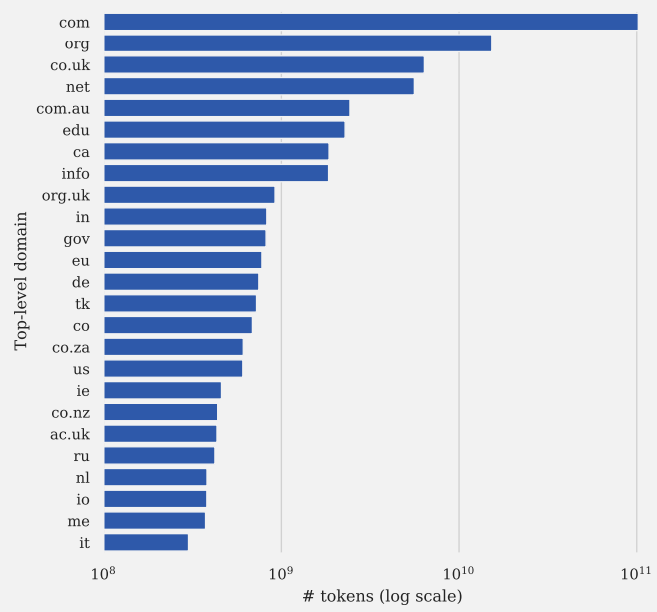 Captura de pantalla de Documentación de grandes corpus de texto web: un estudio de caso sobre el colosal corpus limpio rastreado
Captura de pantalla de Documentación de grandes corpus de texto web: un estudio de caso sobre el colosal corpus limpio rastreadoSi está interesado en obtener más información sobre el conjunto de datos C4, le recomiendo leer Documentación de grandes corpus de texto web: un estudio de caso sobre el colosal corpus limpio rastreado (PDF) así como el trabajo de investigación original de 2020 (PDF) para el que se creó C4.
¿Qué podrían ser los datos de los diálogos de los foros públicos?
El 50% de los datos de entrenamiento provienen de “datos de diálogos de foros públicos.”
Eso es todo lo que dice el artículo de investigación de LaMDA de Google sobre estos datos de entrenamiento.
Si uno tuviera que adivinar, Reddit y otras comunidades importantes como StackOverflow son apuestas seguras.
Reddit se usa en muchos conjuntos de datos importantes, como los desarrollado por OpenAI llamado WebText2 (PDF)una aproximación de código abierto de WebText2 llamada OpenWebText2 y del propio Google WebText-like (PDF) conjunto de datos de 2020.
Google también publicó detalles de otro conjunto de datos de sitios de diálogo público un mes antes de la publicación del artículo de LaMDA.
Este conjunto de datos que contiene sitios de diálogo público se llama MassiveWeb.
No estamos especulando que el conjunto de datos de MassiveWeb se utilizó para entrenar a LaMDA.
Pero contiene un buen ejemplo de lo que Google eligió para otro modelo de lenguaje centrado en el diálogo.
MassiveWeb fue creado por DeepMind, que es propiedad de Google.
Fue diseñado para ser utilizado por un gran modelo de lenguaje llamado Gopher (enlace al PDF del trabajo de investigación).
MassiveWeb utiliza fuentes web de diálogo que van más allá de Reddit para evitar crear un sesgo hacia los datos influenciados por Reddit.
Todavía usa Reddit. Pero también contiene datos extraídos de muchos otros sitios.
Los sitios de diálogo público incluidos en MassiveWeb son:
- Quora
- YouTube
- Medio
- Desbordamiento de pila
Nuevamente, esto no sugiere que LaMDA haya sido capacitado con los sitios anteriores.
Solo tiene la intención de mostrar lo que Google podría haber usado, al mostrar un conjunto de datos en el que Google estaba trabajando casi al mismo tiempo que LaMDA, uno que contiene sitios de tipo foro.
El 37,5% restante
El último grupo de fuentes de datos son:
- 12,5 % de documentos de código de sitios relacionados con la programación, como sitios de preguntas y respuestas, tutoriales, etc.
- 12,5% Wikipedia (inglés)
- 6,25% Documentos web en inglés
- 6,25% Documentos web que no están en inglés.
Google no especifica qué sitios están en el Programación de sitios de preguntas y respuestas categoría que constituye el 12,5% del conjunto de datos en el que se entrenó LaMDA.
Así que solo podemos especular.
Stack Overflow y Reddit parecen opciones obvias, especialmente porque se incluyeron en el conjunto de datos de MassiveWeb.
Qué «tutoriales¿Se rastrearon los sitios? Solo podemos especular cuáles pueden ser esos sitios de «tutoriales».
Eso deja las últimas tres categorías de contenido, dos de las cuales son extremadamente vagas.
Wikipedia en inglés no necesita discusión, todos conocemos Wikipedia.
Pero los dos siguientes no se explican:
Inglés y no inglés Las páginas web de idiomas son una descripción general del 13% de los sitios incluidos en la base de datos.
Esa es toda la información que da Google sobre esta parte de los datos de entrenamiento.
¿Debe Google ser transparente sobre los conjuntos de datos utilizados para Bard?
Algunos editores se sienten incómodos de que sus sitios se utilicen para entrenar sistemas de inteligencia artificial porque, en su opinión, esos sistemas podrían en el futuro hacer que sus sitios web queden obsoletos y desaparezcan.
Queda por ver si eso es cierto o no, pero es una preocupación genuina expresada por los editores y los miembros de la comunidad de marketing de búsqueda.
Google es frustrantemente vago sobre los sitios web utilizados para entrenar a LaMDA, así como sobre qué tecnología se utilizó para raspar los sitios web en busca de datos.
Como se vio en el análisis del conjunto de datos C4, la metodología de elegir qué contenido de sitio web usar para entrenar grandes modelos de lenguaje puede afectar la calidad del modelo de lenguaje al excluir a ciertas poblaciones.
¿Debería Google ser más transparente sobre qué sitios se utilizan para entrenar su IA o al menos publicar un informe de transparencia fácil de encontrar sobre los datos que se utilizaron?
Imagen destacada de Shutterstock/Asier Romero
#Google #Bard #qué #sitios #usaron #para #entrenarlo


